Odoo压力测试实践指南(Locust)
📋 目录
概述
Locust 框架介绍
Locust 是一个开源的、基于 Python 的负载测试工具,用于测试 Web 应用和 API 的性能。它允许使用 Python 代码定义用户行为,支持分布式测试,并提供实时 Web UI 监控测试结果。
Locust 的核心优势
- Python 原生:使用 Python 编写测试脚本,易于学习和维护
- 分布式支持:可以在多台机器上运行,模拟大规模负载
- 实时监控:提供 Web UI 实时查看测试统计和图表
- 灵活的任务定义:可以精确模拟真实用户行为
- 丰富的统计数据:提供详细的性能指标和报告
- 事件驱动:支持事件监听器,可以自定义测试行为
为什么选择 Locust 进行 Odoo 压力测试
- 易于集成:Odoo 使用 XML-RPC/JSON-RPC API,Locust 可以轻松调用这些 API
- 真实模拟:可以模拟真实的用户操作流程,而不仅仅是简单的 HTTP 请求
- 可扩展性:支持分布式测试,可以模拟大规模用户并发
- 详细指标:提供响应时间、吞吐量、错误率等关键指标
- 成本效益:开源免费,无需购买商业工具
适用场景和用例
- 性能基准测试:建立系统性能基线,了解系统在不同负载下的表现
- 容量规划:确定系统能够支持的最大用户数和并发数
- 性能回归测试:在代码变更后验证系统性能是否下降
- 瓶颈识别:找出系统性能瓶颈,优化关键路径
- 负载均衡验证:验证负载均衡配置是否有效
- 压力测试:在系统上线前进行压力测试,确保系统稳定
架构设计
整体架构图
┌─────────────────────────────────────────────────────────────┐
│ Locust Master │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ OdooUser (基类) │ │
│ │ - 登录/登出逻辑 │ │
│ │ - call_kw 封装 │ │
│ │ - 会话管理 │ │
│ └───────────────────────────────────────────────────────┘ │
│ │ │
│ ┌─────────────────┼─────────────────┐ │
│ │ │ │ │
│ ┌─────▼─────┐ ┌──────▼──────┐ ┌──────▼──────┐ │
│ │ OdooPRUser│ │ OdooPOUser │ │ OdooSOUser │ │
│ │ (采购申请)│ │ (采购订单) │ │ (销售订单) │ │
│ └─────┬─────┘ └──────┬──────┘ └──────┬──────┘ │
│ │ │ │ │
│ ┌─────▼─────┐ ┌──────▼──────┐ ┌──────▼──────┐ │
│ │TaskSet │ │ TaskSet │ │ TaskSet │ │
│ │PR Tasks │ │ PO Tasks │ │ SO Tasks │ │
│ └───────────┘ └─────────────┘ └────────────┘ │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ Odoo Server │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ Web Layer (Nginx/Apache) │ │
│ └───────────────────────────────────────────────────────┘ │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ Application Layer (Odoo) │ │
│ │ - XML-RPC / JSON-RPC API │ │
│ │ - ORM Layer │ │
│ └───────────────────────────────────────────────────────┘ │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ Database Layer (PostgreSQL) │ │
│ └───────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
核心组件设计
1. OdooUser 基类
职责:
- 封装 Odoo 登录/登出逻辑
- 提供统一的 API 调用接口(call_kw)
- 管理用户会话和上下文
- 处理错误和异常
2. 具体用户类
职责:
- 定义特定角色的用户类型
- 关联对应的任务集
- 加载用户数据
3. TaskSet 任务集
职责:
- 定义特定业务场景的任务集合
- 实现具体的业务操作
- 管理任务权重和依赖关系
4. 用户数据加载器
职责:
- 从文件加载用户数据(Excel/CSV/JSON)
- 验证用户数据完整性
- 提供用户数据访问接口
Locust 与 Odoo 的交互方式
Locust User 执行流程:
1. 用户启动 (on_start)
└─> 登录 Odoo
└─> 获取 CSRF Token
└─> 调用 /web/session/authenticate
└─> 保存 Session ID 和 User Context
2. 执行任务 (TaskSet)
└─> 调用 call_kw 方法
└─> 构建 JSON-RPC 请求
└─> 发送 POST 到 /web/dataset/call_kw
└─> 处理响应结果
└─> 记录性能指标
3. 用户停止 (on_stop)
└─> 调用 /web/session/logout
└─> 清理会话
设计原则和模式
- 单一职责原则:每个类只负责一个功能
- 开闭原则:对扩展开放,对修改关闭
- 依赖倒置:依赖抽象而非具体实现
- 模板方法模式:基类定义骨架,子类实现细节
- 策略模式:不同的任务集代表不同的策略
- 工厂模式:用户数据加载器可以看作工厂
项目结构
推荐的项目目录结构
odo-locust-test/
├── locustfile.py # 主测试文件,定义用户类
├── requirements.txt # Python 依赖包
├── README.md # 项目说明文档
│
├── config/ # 配置文件目录
│ ├── __init__.py
│ ├── settings.py # 测试配置
│ └── environments.yaml # 环境配置(开发/测试/生产)
│
├── taskset/ # 任务集模块
│ ├── __init__.py
│ ├── base_task.py # 基础任务类
│ ├── purchase_request.py # 采购申请任务
│ ├── purchase_order.py # 采购订单任务
│ ├── sale_order.py # 销售订单任务
│ ├── inventory.py # 库存管理任务
│ └── manufacturing.py # 生产任务
│
├── utils/ # 工具模块
│ ├── __init__.py
│ ├── odoo_client.py # Odoo 客户端封装
│ ├── user_loader.py # 用户数据加载器
│ ├── logger.py # 日志配置
│ └── helpers.py # 辅助函数
│
├── user_data/ # 用户数据文件
│ ├── purchase_users.xlsx # 采购用户数据
│ ├── sale_users.xlsx # 销售用户数据
│ ├── inventory_users.xlsx # 库存用户数据
│ └── manufacturing_users.xlsx # 生产用户数据
│
├── reports/ # 测试报告目录
│ ├── html/ # HTML 报告
│ └── csv/ # CSV 报告
│
└── tests/ # 单元测试(可选)
├── __init__.py
└── test_user_loader.py
各模块的职责说明
locustfile.py
- 定义用户类(OdooUser 基类和具体用户类)
- 配置测试参数
- 注册事件监听器
config/
- 管理测试配置
- 环境配置管理
- 参数验证
taskset/
- 实现业务场景的任务集
- 定义任务权重
- 实现业务逻辑
utils/
- 提供通用工具函数
- Odoo API 封装
- 用户数据管理
- 日志配置
user_data/
- 存储测试用户数据
- 支持多种格式(Excel/CSV/JSON)
reports/
- 存储测试报告
- 历史报告归档
文件组织最佳实践
- 模块化设计:将不同功能分离到不同模块
- 清晰的命名:使用有意义的文件名和类名
- 配置分离:将配置信息从代码中分离出来
- 可扩展性:便于添加新的用户类型和任务集
- 文档完整:每个模块都有清晰的文档说明
核心组件实现
Odoo 用户基类(OdooUser)实现
"""
Odoo 用户基类
提供登录、登出、API 调用等通用功能
"""
import random
import logging
from typing import Dict, List, Optional, Any
from locust import HttpUser, task, between
from locust.exception import RescheduleTask
logger = logging.getLogger(__name__)
class OdooUser(HttpUser):
"""
Odoo 用户基类
提供所有用户类型的通用功能:
- 登录/登出
- API 调用封装
- 会话管理
- 错误处理
"""
abstract = True # 标记为抽象类,不直接实例化
# 用户行为等待时间(秒)
wait_time = between(1, 5)
# Odoo 服务器地址(子类可以覆盖)
host = "https://erp.example.com"
def __init__(self, *args, **kwargs):
"""
初始化用户
子类应该在 __init__ 中设置:
- self.database: 数据库名称
- self.username: 用户名
- self.password: 密码
"""
super().__init__(*args, **kwargs)
# Odoo 配置(子类需要设置)
self.database: Optional[str] = None
self.username: Optional[str] = None
self.password: Optional[str] = None
# 会话信息
self.uid: Optional[int] = None
self.session_id: Optional[str] = None
self.user_context: Dict[str, Any] = {}
self.csrf_token: Optional[str] = None
# 登录信息
self.login_account: Optional[str] = None
self.user_name: Optional[str] = None
def on_start(self):
"""
用户开始测试时的初始化操作
执行顺序:
1. 初始化会话信息
2. 执行登录
"""
logger.info(f"用户 {self.__class__.__name__} 开始初始化")
# 验证配置
if not all([self.database, self.username, self.password]):
logger.error(f"用户配置不完整: database={self.database}, username={self.username}")
raise RescheduleTask()
# 初始化会话信息
self.session_id = None
self.uid = None
self.user_context = {}
self.csrf_token = None
# 执行登录
self.login()
def on_stop(self):
"""
用户停止测试时的清理操作
执行登出操作,清理会话
"""
if self.session_id:
try:
self.client.get(
"/web/session/logout",
name="GET /web/session/logout",
catch_response=True
)
logger.info(f"用户 {self.uid} ({self.login_account}) 已登出")
except Exception as e:
logger.error(f"登出失败: {e}")
def login(self) -> bool:
"""
登录 Odoo 并获取 session 信息
Returns:
bool: 登录是否成功
"""
try:
# 步骤 1: 获取登录页面,提取 CSRF token
response = self.client.get("/web/login", name="Login page")
if response.status_code != 200:
logger.error(f"获取登录页面失败: HTTP {response.status_code}")
return False
# 提取 CSRF token
csrf_anchor = '<input type="hidden" name="csrf_token" value="'
csrf_token = response.text.partition(csrf_anchor)[2].partition('"')[0]
if not csrf_token:
logger.error("无法提取 CSRF token")
return False
self.csrf_token = csrf_token
# 步骤 2: 执行登录请求
login_data = {
"jsonrpc": "2.0",
"method": "call",
"id": random.randint(1, 1000000),
"csrf_token": csrf_token,
"params": {
"db": self.database,
"login": self.username,
"password": self.password,
}
}
with self.client.post(
"/web/session/authenticate",
json=login_data,
catch_response=True,
name="Login"
) as response:
if response.status_code == 200:
result = response.json()
# 检查登录结果
if "result" in result and result["result"].get("uid"):
# 保存会话信息
self.uid = result["result"]["uid"]
self.login_account = result["result"].get("username", "")
self.user_name = result["result"].get("name", "")
self.user_context = result["result"].get("user_context", {})
self.session_id = self.client.cookies.get("session_id")
# 保存 cookies
self.client.cookies = response.cookies
logger.info(
f"登录成功: UID={self.uid}, "
f"User={self.user_name}, "
f"Login={self.login_account}"
)
response.success()
return True
else:
# 登录失败
error_data = result.get("error", {})
error_msg = error_data.get("data", {}).get("name", "未知错误")
logger.error(f"登录失败: {error_msg}")
response.failure(f"登录失败: {error_msg}")
return False
else:
logger.error(f"登录请求失败: HTTP {response.status_code}")
response.failure(f"登录失败: HTTP {response.status_code}")
return False
except Exception as e:
logger.error(f"登录过程发生异常: {e}", exc_info=True)
return False
def call_kw(
self,
model: str,
method: str,
args: Optional[List] = None,
kwargs: Optional[Dict] = None,
name: Optional[str] = None,
timeout: Optional[float] = None
) -> Optional[Any]:
"""
调用 Odoo 模型方法
这是与 Odoo 交互的核心方法,封装了 Odoo 的 JSON-RPC API 调用。
Args:
model: Odoo 模型名称(如 'res.partner')
method: 方法名称(如 'search_read')
args: 位置参数列表
kwargs: 关键字参数字典
name: 请求名称(用于 Locust 统计,如果不提供则使用 model.method)
timeout: 请求超时时间(秒)
Returns:
API 调用结果,如果失败则返回 None
"""
# 检查登录状态
if not self.uid:
logger.warning("用户未登录,无法调用 API")
return None
# 构建请求数据
request_data = {
"jsonrpc": "2.0",
"method": "call",
"params": {
"model": model,
"method": method,
"args": args or [],
"kwargs": kwargs or {},
"context": self.user_context
},
"id": random.randint(1, 1000000)
}
# 确定请求名称(用于 Locust 统计)
request_name = name or f"{model}.{method}"
# 发送请求
try:
with self.client.post(
"/web/dataset/call_kw",
json=request_data,
catch_response=True,
name=request_name,
timeout=timeout
) as response:
if response.status_code == 200:
result = response.json()
# 检查结果
if "result" in result:
response.success()
return result["result"]
elif "error" in result:
# API 返回错误
error = result["error"]
error_msg = error.get("message", "Unknown error")
error_data = error.get("data", {})
logger.error(
f"API 调用失败: {request_name}, "
f"错误: {error_msg}, "
f"数据: {error_data}"
)
response.failure(f"API 错误: {error_msg}")
return None
else:
# 响应格式异常
logger.error(f"响应格式异常: {result}")
response.failure("响应格式异常")
return None
else:
# HTTP 错误
logger.error(
f"HTTP 请求失败: {request_name}, "
f"状态码: {response.status_code}"
)
response.failure(f"HTTP {response.status_code}")
return None
except Exception as e:
logger.error(f"API 调用异常: {request_name}, 错误: {e}", exc_info=True)
return None
def is_logged_in(self) -> bool:
"""
检查用户是否已登录
Returns:
bool: 如果已登录返回 True
"""
return self.uid is not None and self.uid > 0
登录/登出逻辑
登录流程已在上面的 login() 方法中实现。关键点:
- 获取 CSRF Token:从登录页面 HTML 中提取
- 构建登录请求:使用 JSON-RPC 格式
- 保存会话信息:UID、Session ID、User Context
- 错误处理:完善的错误处理和日志记录
Odoo API 调用封装(call_kw)
call_kw 方法是与 Odoo 交互的核心,它:
- 统一接口:所有 Odoo API 调用都通过这个方法
- 自动处理:自动添加 User Context
- 错误处理:统一的错误处理机制
- 性能统计:自动记录到 Locust 统计中
会话管理
会话管理包括:
- Session ID:从 Cookie 中获取和保存
- User Context:保存用户上下文信息
- Cookie 管理:自动保存和传递 cookies
- 会话验证:检查登录状态
错误处理机制
错误处理策略:
- 分层处理:登录错误、API 错误、网络错误分别处理
- 日志记录:详细记录错误信息
- 优雅降级:错误时返回 None,不中断测试
- 重试机制:可以结合 Locust 的 RescheduleTask 实现重试
任务集(TaskSet)设计
TaskSet 的基本结构
"""
任务集基类
提供任务集的通用功能
"""
from locust import TaskSet, task, between
from typing import TYPE_CHECKING
if TYPE_CHECKING:
from locust import HttpUser
class BaseTaskSet(TaskSet):
"""
基础任务集类
提供任务集的通用功能:
- 数据缓存
- 辅助方法
- 错误处理
"""
wait_time = between(1, 5)
def __init__(self, parent: "HttpUser"):
"""
初始化任务集
Args:
parent: 父用户对象(OdooUser 实例)
"""
super().__init__(parent=parent)
self._cache = {} # 数据缓存
@property
def user(self) -> "HttpUser":
"""获取父用户对象"""
return self.parent
def _get_cached_data(self, key: str, ttl: int = 300):
"""
获取缓存数据
Args:
key: 缓存键
ttl: 缓存有效期(秒)
Returns:
缓存数据,如果不存在或过期则返回 None
"""
import time
if key in self._cache:
data, timestamp = self._cache[key]
if time.time() - timestamp < ttl:
return data
else:
# 缓存过期,删除
del self._cache[key]
return None
def _set_cached_data(self, key: str, data: any):
"""
设置缓存数据
Args:
key: 缓存键
data: 要缓存的数据
"""
import time
self._cache[key] = (data, time.time())
任务权重设计原则
任务权重表示任务执行的相对频率。设计原则:
- 真实场景模拟:根据实际业务场景分配权重
- 读写比例:通常读取操作比写入操作更频繁
- 用户行为:常见操作权重高,罕见操作权重低
权重分配示例:
class PurchaseRequestTask(BaseTaskSet):
"""采购申请任务集"""
@task(20) # 40% - 查看列表(最常见)
def view_list(self):
"""查看采购申请列表"""
pass
@task(15) # 30% - 浏览详情
def browse_detail(self):
"""浏览采购申请详情"""
pass
@task(10) # 20% - 更新操作
def update(self):
"""更新采购申请"""
pass
@task(5) # 10% - 创建操作(低频)
def create(self):
"""创建采购申请"""
pass
不同业务场景的任务集示例
1. 采购申请任务集
"""
采购申请任务集
"""
import random
import logging
from datetime import datetime
from locust import TaskSet, task, between
from typing import List, Dict, Optional
logger = logging.getLogger(__name__)
class PurchaseRequestTask(BaseTaskSet):
"""
采购申请任务集
模拟采购申请相关的用户操作:
- 查看采购申请列表
- 浏览采购申请详情
- 更新采购申请
- 创建采购申请
"""
wait_time = between(1, 5)
model = "purchase.request"
def __init__(self, parent):
super().__init__(parent)
self.request_list = [] # 缓存的采购申请列表
@task(20)
def view_request_list(self):
"""
查看采购申请列表
权重:20(最常见的操作)
"""
try:
result = self.user.call_kw(
model=self.model,
method="web_search_read",
args=[],
kwargs={
"limit": 50,
"offset": 0,
"domain": [],
"fields": ["id", "name", "date", "state", "amount_total"],
"order": "create_date desc",
"count_limit": 10000,
},
name="Purchase Request - View List"
)
if result and "records" in result:
self.request_list = result["records"][:50] # 限制缓存数量
logger.debug(f"加载了 {len(self.request_list)} 条采购申请")
except Exception as e:
logger.error(f"查看采购申请列表失败: {e}")
@task(15)
def browse_request_detail(self):
"""
浏览采购申请详情
权重:15
"""
if not self.request_list:
self.view_request_list()
if self.request_list:
request = random.choice(self.request_list)
result = self.user.call_kw(
model=self.model,
method="read",
args=[[request["id"]]],
kwargs={
"fields": [
"id", "name", "date", "state",
"partner_id", "amount_total", "line_ids"
]
},
name="Purchase Request - Read Detail"
)
if result:
logger.debug(f"浏览采购申请: {result[0].get('name', '')}")
@task(10)
def update_request(self):
"""
更新采购申请
权重:10
"""
if not self.request_list:
self.view_request_list()
# 只更新自己创建的申请
my_requests = self.user.call_kw(
model=self.model,
method="search_read",
args=[],
kwargs={
"limit": 10,
"domain": [["create_uid", "=", self.user.uid]],
"fields": ["id", "name"]
},
name="Purchase Request - Search My Requests"
)
if my_requests:
request = random.choice(my_requests)
update_result = self.user.call_kw(
model=self.model,
method="write",
args=[[request["id"]], {
"note": f"Locust测试更新 - {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}"
}],
name="Purchase Request - Update"
)
if update_result:
logger.info(f"成功更新采购申请: {request.get('name', '')}")
@task(5)
def create_request(self):
"""
创建采购申请
权重:5(低频操作)
"""
try:
# 获取必要的基础数据
partner_id = self._get_partner()
product_id = self._get_product()
if not partner_id or not product_id:
logger.warning("无法获取创建采购申请所需的基础数据")
return
# 创建采购申请
vals = {
"partner_id": partner_id,
"date": datetime.now().strftime("%Y-%m-%d"),
"line_ids": [
(0, 0, {
"product_id": product_id,
"product_qty": random.randint(1, 10),
"price_unit": random.uniform(10.0, 1000.0),
})
],
"note": f"Locust测试创建 - {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}"
}
result = self.user.call_kw(
model=self.model,
method="create",
args=[vals],
name="Purchase Request - Create"
)
if result:
logger.info(f"成功创建采购申请: ID={result}")
except Exception as e:
logger.error(f"创建采购申请失败: {e}", exc_info=True)
def _get_partner(self) -> Optional[int]:
"""获取供应商"""
result = self.user.call_kw(
model="res.partner",
method="search",
args=[[["supplier_rank", ">", 0]]],
kwargs={"limit": 10},
name="Purchase Request - Get Partner"
)
return random.choice(result) if result else None
def _get_product(self) -> Optional[int]:
"""获取产品"""
result = self.user.call_kw(
model="product.product",
method="search",
args=[[["purchase_ok", "=", True]]],
kwargs={"limit": 10},
name="Purchase Request - Get Product"
)
return random.choice(result) if result else None
2. 采购订单任务集
"""
采购订单任务集
"""
from locust import TaskSet, task, between
from typing import List, Optional
class PurchaseOrderTask(BaseTaskSet):
"""采购订单任务集"""
wait_time = between(1, 5)
model = "purchase.order"
def __init__(self, parent):
super().__init__(parent)
self.order_list = []
@task(25)
def view_order_list(self):
"""查看采购订单列表"""
result = self.user.call_kw(
model=self.model,
method="web_search_read",
args=[],
kwargs={
"limit": 50,
"domain": [],
"fields": ["id", "name", "date_order", "state", "amount_total"],
"order": "create_date desc",
},
name="Purchase Order - View List"
)
if result and "records" in result:
self.order_list = result["records"][:50]
@task(15)
def browse_order_detail(self):
"""浏览采购订单详情"""
if not self.order_list:
self.view_order_list()
if self.order_list:
order = random.choice(self.order_list)
self.user.call_kw(
model=self.model,
method="read",
args=[[order["id"]]],
kwargs={"fields": ["id", "name", "partner_id", "order_line", "state"]},
name="Purchase Order - Read Detail"
)
@task(10)
def update_order(self):
"""更新采购订单"""
# 实现更新逻辑
pass
@task(2)
def create_order(self):
"""创建采购订单"""
# 实现创建逻辑
pass
3. 销售订单任务集
"""
销售订单任务集
"""
from locust import TaskSet, task, between
class SaleOrderTask(BaseTaskSet):
"""销售订单任务集"""
wait_time = between(1, 5)
model = "sale.order"
def __init__(self, parent):
super().__init__(parent)
self.order_list = []
@task(30)
def view_order_list(self):
"""查看销售订单列表"""
result = self.user.call_kw(
model=self.model,
method="web_search_read",
args=[],
kwargs={
"limit": 50,
"domain": [],
"fields": ["id", "name", "date_order", "state", "amount_total"],
"order": "create_date desc",
},
name="Sale Order - View List"
)
if result and "records" in result:
self.order_list = result["records"][:50]
@task(20)
def browse_order_detail(self):
"""浏览销售订单详情"""
if not self.order_list:
self.view_order_list()
if self.order_list:
order = random.choice(self.order_list)
self.user.call_kw(
model=self.model,
method="read",
args=[[order["id"]]],
kwargs={"fields": ["id", "name", "partner_id", "order_line", "state"]},
name="Sale Order - Read Detail"
)
@task(15)
def update_order(self):
"""更新销售订单"""
# 实现更新逻辑
pass
@task(3)
def create_order(self):
"""创建销售订单"""
# 实现创建逻辑
pass
4. 库存管理任务集
"""
库存管理任务集
"""
from locust import TaskSet, task, between
class InventoryTask(BaseTaskSet):
"""库存管理任务集"""
wait_time = between(1, 5)
model = "stock.picking"
def __init__(self, parent):
super().__init__(parent)
self.picking_list = []
@task(25)
def view_picking_list(self):
"""查看库存调拨列表"""
result = self.user.call_kw(
model=self.model,
method="web_search_read",
args=[],
kwargs={
"limit": 50,
"domain": [],
"fields": ["id", "name", "state", "date", "location_id", "location_dest_id"],
"order": "create_date desc",
},
name="Inventory - View Picking List"
)
if result and "records" in result:
self.picking_list = result["records"][:50]
@task(15)
def browse_picking_detail(self):
"""浏览库存调拨详情"""
if not self.picking_list:
self.view_picking_list()
if self.picking_list:
picking = random.choice(self.picking_list)
self.user.call_kw(
model=self.model,
method="read",
args=[[picking["id"]]],
kwargs={"fields": ["id", "name", "move_ids", "state"]},
name="Inventory - Read Picking Detail"
)
@task(10)
def confirm_picking(self):
"""确认库存调拨"""
# 实现确认逻辑
pass
@task(5)
def create_picking(self):
"""创建库存调拨"""
# 实现创建逻辑
pass
5. 生产任务集
"""
生产任务集
"""
from locust import TaskSet, task, between
class ManufacturingTask(BaseTaskSet):
"""生产任务集"""
wait_time = between(1, 5)
model = "mrp.production"
def __init__(self, parent):
super().__init__(parent)
self.production_list = []
@task(20)
def view_production_list(self):
"""查看生产订单列表"""
result = self.user.call_kw(
model=self.model,
method="web_search_read",
args=[],
kwargs={
"limit": 50,
"domain": [["state", "!=", "cancel"]],
"fields": ["id", "name", "state", "date_planned_start", "product_id"],
"order": "create_date desc",
},
name="Manufacturing - View Production List"
)
if result and "records" in result:
self.production_list = result["records"][:50]
@task(15)
def browse_production_detail(self):
"""浏览生产订单详情"""
if not self.production_list:
self.view_production_list()
if self.production_list:
production = random.choice(self.production_list)
self.user.call_kw(
model=self.model,
method="read",
args=[[production["id"]]],
kwargs={"fields": ["id", "name", "bom_id", "move_raw_ids", "state"]},
name="Manufacturing - Read Production Detail"
)
@task(10)
def update_production(self):
"""更新生产订单"""
# 实现更新逻辑
pass
@task(3)
def create_production(self):
"""创建生产订单"""
# 实现创建逻辑
pass
任务间的依赖关系
任务可以存在依赖关系,例如:
class PurchaseRequestTask(BaseTaskSet):
"""采购申请任务集"""
@task(20)
def view_list(self):
"""查看列表"""
# 这个任务会更新 self.request_list
pass
@task(15)
def browse_detail(self):
"""浏览详情 - 依赖 view_list"""
if not self.request_list:
# 如果列表为空,先执行查看列表
self.view_list()
# 然后执行浏览详情
if self.request_list:
# 浏览详情逻辑
pass
用户数据管理
用户数据加载方案
1. Excel 文件加载(推荐)
"""
Excel 用户数据加载器
"""
import random
import logging
from typing import Dict, List, Optional
from openpyxl import load_workbook
logger = logging.getLogger(__name__)
class ExcelUserLoader:
"""
Excel 用户数据加载器
从 Excel 文件加载用户数据,支持:
- 随机获取用户
- 按索引获取用户
- 数据验证
- 缓存机制
"""
def __init__(self, excel_file_path: str, sheet_name: Optional[str] = None):
"""
初始化加载器
Args:
excel_file_path: Excel 文件路径
sheet_name: 工作表名称,如果为 None 则使用活动工作表
"""
self.excel_file_path = excel_file_path
self.sheet_name = sheet_name
self.user_data: List[Dict] = []
self._load_data()
def _load_data(self):
"""加载用户数据"""
try:
# 打开工作簿(只读模式,提高性能)
workbook = load_workbook(self.excel_file_path, read_only=True)
sheet = workbook[self.sheet_name] if self.sheet_name else workbook.active
# 读取表头
headers = [cell.value for cell in sheet[1]]
# 读取数据行
for row in sheet.iter_rows(min_row=2, values_only=True):
if any(cell is not None for cell in row):
user_dict = dict(zip(headers, row))
# 数据验证
if self._validate_user(user_dict):
self.user_data.append(user_dict)
workbook.close()
logger.info(
f"从 {self.excel_file_path} 加载了 {len(self.user_data)} 条用户数据"
)
except Exception as e:
logger.error(f"加载用户数据失败: {e}", exc_info=True)
raise
def _validate_user(self, user_dict: Dict) -> bool:
"""
验证用户数据完整性
Args:
user_dict: 用户数据字典
Returns:
bool: 如果数据有效返回 True
"""
required_fields = ['login', 'password']
return all(
field in user_dict and user_dict[field]
for field in required_fields
)
def get_random_user(self) -> Dict:
"""
随机获取一个用户
Returns:
Dict: 用户数据字典
Raises:
ValueError: 如果没有可用用户
"""
if not self.user_data:
raise ValueError(f"没有可用的用户数据: {self.excel_file_path}")
return random.choice(self.user_data)
def get_user_by_index(self, index: int) -> Dict:
"""
按索引获取用户(用于固定用户分配)
Args:
index: 用户索引
Returns:
Dict: 用户数据字典
Raises:
IndexError: 如果索引超出范围
"""
if 0 <= index < len(self.user_data):
return self.user_data[index]
raise IndexError(f"用户索引超出范围: {index} (总数: {len(self.user_data)})")
def get_all_users(self) -> List[Dict]:
"""
获取所有用户
Returns:
List[Dict]: 所有用户数据列表
"""
return self.user_data.copy()
def get_user_count(self) -> int:
"""
获取用户数量
Returns:
int: 用户数量
"""
return len(self.user_data)
2. CSV 文件加载
"""
CSV 用户数据加载器
"""
import csv
import random
import logging
from typing import Dict, List
from pathlib import Path
logger = logging.getLogger(__name__)
class CSVUserLoader:
"""CSV 用户数据加载器"""
def __init__(self, csv_file_path: str):
"""
初始化加载器
Args:
csv_file_path: CSV 文件路径
"""
self.csv_file_path = csv_file_path
self.user_data: List[Dict] = []
self._load_data()
def _load_data(self):
"""加载用户数据"""
try:
with open(self.csv_file_path, 'r', encoding='utf-8') as f:
reader = csv.DictReader(f)
for row in reader:
if self._validate_user(row):
self.user_data.append(row)
logger.info(
f"从 {self.csv_file_path} 加载了 {len(self.user_data)} 条用户数据"
)
except Exception as e:
logger.error(f"加载用户数据失败: {e}", exc_info=True)
raise
def _validate_user(self, user_dict: Dict) -> bool:
"""验证用户数据"""
required_fields = ['login', 'password']
return all(
field in user_dict and user_dict[field]
for field in required_fields
)
def get_random_user(self) -> Dict:
"""随机获取一个用户"""
if not self.user_data:
raise ValueError(f"没有可用的用户数据: {self.csv_file_path}")
return random.choice(self.user_data)
3. JSON 文件加载
"""
JSON 用户数据加载器
"""
import json
import random
import logging
from typing import Dict, List
from pathlib import Path
logger = logging.getLogger(__name__)
class JSONUserLoader:
"""JSON 用户数据加载器"""
def __init__(self, json_file_path: str):
"""
初始化加载器
Args:
json_file_path: JSON 文件路径
"""
self.json_file_path = json_file_path
self.user_data: List[Dict] = []
self._load_data()
def _load_data(self):
"""加载用户数据"""
try:
with open(self.json_file_path, 'r', encoding='utf-8') as f:
data = json.load(f)
# 支持多种 JSON 格式
if isinstance(data, list):
self.user_data = data
elif isinstance(data, dict) and 'users' in data:
self.user_data = data['users']
else:
raise ValueError("JSON 格式不支持")
# 验证数据
self.user_data = [
user for user in self.user_data
if self._validate_user(user)
]
logger.info(
f"从 {self.json_file_path} 加载了 {len(self.user_data)} 条用户数据"
)
except Exception as e:
logger.error(f"加载用户数据失败: {e}", exc_info=True)
raise
def _validate_user(self, user_dict: Dict) -> bool:
"""验证用户数据"""
required_fields = ['login', 'password']
return all(
field in user_dict and user_dict[field]
for field in required_fields
)
def get_random_user(self) -> Dict:
"""随机获取一个用户"""
if not self.user_data:
raise ValueError(f"没有可用的用户数据: {self.json_file_path}")
return random.choice(self.user_data)
用户数据验证
用户数据验证应该检查:
- 必需字段:login、password 必须存在
- 数据类型:字段类型正确
- 数据格式:格式符合要求(如邮箱格式)
- 数据完整性:没有空值或无效值
多用户类型支持
"""
用户数据管理器
管理多种类型的用户数据
"""
from typing import Dict, Optional
from utils.user_loader import ExcelUserLoader
class UserDataManager:
"""用户数据管理器"""
def __init__(self):
"""初始化管理器"""
self.loaders: Dict[str, ExcelUserLoader] = {}
def register_loader(self, user_type: str, loader: ExcelUserLoader):
"""
注册用户数据加载器
Args:
user_type: 用户类型(如 'purchase', 'sale')
loader: 用户数据加载器
"""
self.loaders[user_type] = loader
def get_user(self, user_type: str) -> Dict:
"""
获取指定类型的用户
Args:
user_type: 用户类型
Returns:
Dict: 用户数据字典
Raises:
KeyError: 如果用户类型不存在
"""
if user_type not in self.loaders:
raise KeyError(f"用户类型不存在: {user_type}")
return self.loaders[user_type].get_random_user()
用户分配策略
- 随机分配:每次随机选择用户(推荐)
- 轮询分配:按顺序分配用户
- 固定分配:每个 Locust 用户固定使用一个测试用户
- 权重分配:根据用户类型权重分配
# 随机分配(推荐)
user = user_loader.get_random_user()
# 轮询分配
user_index = self.user_index % user_loader.get_user_count()
user = user_loader.get_user_by_index(user_index)
self.user_index += 1
# 固定分配(在 __init__ 中)
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.fixed_user = user_loader.get_random_user()
最佳实践
代码组织原则
✅ 推荐做法
- 模块化设计:将不同功能分离到不同模块
- 清晰的命名:使用有意义的文件名、类名、方法名
- 单一职责:每个类、方法只负责一个功能
- 配置分离:将配置信息从代码中分离出来
- 文档完整:关键代码都有注释和文档字符串
❌ 避免做法
- 将所有代码写在一个文件中
- 使用模糊的命名(如
data,func) - 一个方法做太多事情
- 硬编码配置信息
- 缺少文档和注释
任务权重设计指南
任务权重应该反映真实用户行为:
# ✅ 推荐:根据真实场景分配权重
class PurchaseRequestTask(BaseTaskSet):
@task(20) # 40% - 查看列表(最常见)
def view_list(self):
pass
@task(15) # 30% - 浏览详情
def browse_detail(self):
pass
@task(10) # 20% - 更新操作
def update(self):
pass
@task(5) # 10% - 创建操作(低频)
def create(self):
pass
# ❌ 避免:权重分配不合理
class PurchaseRequestTask(BaseTaskSet):
@task(1) # 所有任务权重相同,不符合真实场景
def view_list(self):
pass
@task(1)
def create(self):
pass
错误处理最佳实践
✅ 推荐做法
@task(5)
def risky_operation(self):
"""有风险的操作"""
try:
# 检查前置条件
if not self.user.is_logged_in():
logger.warning("用户未登录,跳过操作")
return
# 执行操作
result = self.user.call_kw(...)
# 验证结果
if not result:
logger.warning("操作返回空结果")
return
# 处理结果
logger.info(f"操作成功: {result}")
except Exception as e:
# 记录错误,但不抛出异常(让 Locust 继续运行)
logger.error(f"操作失败: {e}", exc_info=True)
❌ 避免做法
@task(5)
def risky_operation(self):
"""没有错误处理"""
result = self.user.call_kw(...) # 可能抛出异常
# 没有验证结果
# 没有错误处理
数据缓存策略
✅ 推荐做法
class MyTaskSet(BaseTaskSet):
def __init__(self, parent):
super().__init__(parent)
self._cache = {}
self._cache_ttl = 300 # 缓存有效期 5 分钟
def _get_partners(self, force_refresh=False):
"""获取合作伙伴(带缓存)"""
import time
cache_key = "partners"
now = time.time()
# 检查缓存
if not force_refresh:
cached_data = self._get_cached_data(cache_key, self._cache_ttl)
if cached_data:
return cached_data
# 从 API 获取
result = self.user.call_kw(
model="res.partner",
method="search_read",
args=[],
kwargs={"limit": 50},
name="Get Partners"
)
# 更新缓存
if result:
self._set_cached_data(cache_key, result)
return result
❌ 避免做法
# 每次都要查询,没有缓存
def _get_partners(self):
return self.user.call_kw(...) # 每次都查询
性能优化建议
- 减少不必要的请求:使用缓存避免重复查询
- 限制查询数量:使用
limit限制查询结果 - 只查询需要的字段:指定
fields参数,避免查询所有字段 - 批量操作:尽可能使用批量操作而非逐个操作
- 优化查询域:使用索引字段构建查询域
代码复用技巧
- 基类封装通用功能:
OdooUser基类封装登录、API 调用等 - 工具函数提取:将通用逻辑提取为工具函数
- 配置统一管理:使用配置文件统一管理参数
- 任务集继承:基础任务集提供通用功能
推荐做法 vs 避免做法
代码组织
| 推荐做法 ✅ | 避免做法 ❌ |
|---|---|
| 模块化设计,功能分离 | 所有代码在一个文件 |
| 清晰的命名规范 | 使用模糊的命名 |
| 配置与代码分离 | 硬编码配置 |
| 完整的文档注释 | 缺少文档 |
错误处理
| 推荐做法 ✅ | 避免做法 ❌ |
|---|---|
| 完善的 try-except | 没有错误处理 |
| 详细的日志记录 | 缺少日志 |
| 优雅降级 | 异常中断测试 |
| 结果验证 | 不验证结果 |
性能优化
| 推荐做法 ✅ | 避免做法 ❌ |
|---|---|
| 使用缓存 | 每次都查询 |
| 限制查询数量 | 查询所有数据 |
| 只查询需要的字段 | 查询所有字段 |
| 批量操作 | 逐个操作 |
配置管理
配置文件设计(Python)
"""
测试配置
"""
import os
from typing import Tuple, Optional
from pathlib import Path
class Settings:
"""测试配置类"""
# Odoo 服务器配置
ODOO_HOST = os.getenv("ODOO_HOST", "https://erp.example.com")
ODOO_DATABASE = os.getenv("ODOO_DATABASE", "odoo")
# 用户数据配置
USER_DATA_DIR = Path(__file__).parent.parent / "user_data"
# Locust 配置
DEFAULT_WAIT_TIME: Tuple[int, int] = (1, 5)
DEFAULT_WEIGHT = 1
# 日志配置
LOG_LEVEL = os.getenv("LOG_LEVEL", "INFO")
LOG_FORMAT = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
LOG_FILE = None # 如果设置,日志将写入文件
# 性能配置
MAX_CACHE_SIZE = 50
CACHE_TTL = 300 # 秒
# API 配置
DEFAULT_TIMEOUT = 30 # 秒
MAX_RETRIES = 3
@classmethod
def validate(cls):
"""验证配置"""
errors = []
if not cls.ODOO_HOST:
errors.append("ODOO_HOST 未设置")
if not cls.ODOO_DATABASE:
errors.append("ODOO_DATABASE 未设置")
if errors:
raise ValueError(f"配置错误: {', '.join(errors)}")
return True
环境变量管理
# .env 文件
ODOO_HOST=https://erp.example.com
ODOO_DATABASE=odoo
LOG_LEVEL=INFO
# 使用 python-dotenv 加载
from dotenv import load_dotenv
load_dotenv()
多环境支持(开发/测试/生产)
"""
环境配置
"""
import os
from typing import Dict
class EnvironmentConfig:
"""环境配置类"""
ENVIRONMENTS = {
"development": {
"host": "http://localhost:8069",
"database": "odoo_dev",
"log_level": "DEBUG",
},
"testing": {
"host": "https://erp-test.example.com",
"database": "odoo_test",
"log_level": "INFO",
},
"production": {
"host": "https://erp.example.com",
"database": "odoo",
"log_level": "WARNING",
}
}
@classmethod
def get_config(cls, env: str = None) -> Dict:
"""
获取环境配置
Args:
env: 环境名称,如果为 None 则从环境变量获取
Returns:
Dict: 环境配置字典
"""
if env is None:
env = os.getenv("ENVIRONMENT", "development")
if env not in cls.ENVIRONMENTS:
raise ValueError(f"未知环境: {env}")
return cls.ENVIRONMENTS[env]
配置验证
"""
配置验证
"""
from typing import List
class ConfigValidator:
"""配置验证器"""
@staticmethod
def validate_odoo_config(config: Dict) -> List[str]:
"""
验证 Odoo 配置
Args:
config: 配置字典
Returns:
List[str]: 错误列表,如果为空则表示配置有效
"""
errors = []
# 验证必需字段
required_fields = ['host', 'database']
for field in required_fields:
if field not in config or not config[field]:
errors.append(f"缺少必需字段: {field}")
# 验证格式
if 'host' in config:
host = config['host']
if not host.startswith(('http://', 'https://')):
errors.append(f"host 格式错误: {host}")
return errors
运行与监控
Locust 基本运行命令
1. 启动 Web UI(推荐用于开发和调试)
# 基本启动
locust -f locustfile.py --host=https://erp.example.com
# 指定端口
locust -f locustfile.py --host=https://erp.example.com --web-port=8089
# 指定 Web UI 地址
locust -f locustfile.py --host=https://erp.example.com --web-host=0.0.0.0
2. 无头模式运行(用于 CI/CD 和生产环境)
# 基本无头模式
locust -f locustfile.py \
--host=https://erp.example.com \
--headless \
--users 100 \
--spawn-rate 10 \
--run-time 5m
# 参数说明:
# --users: 模拟用户数
# --spawn-rate: 用户生成速率(每秒)
# --run-time: 运行时长(5m = 5分钟,1h = 1小时)
3. 生成报告
# 生成 HTML 报告
locust -f locustfile.py \
--host=https://erp.example.com \
--headless \
--users 100 \
--spawn-rate 10 \
--run-time 5m \
--html reports/report.html
# 生成 CSV 报告
locust -f locustfile.py \
--host=https://erp.example.com \
--headless \
--users 100 \
--spawn-rate 10 \
--run-time 5m \
--csv reports/stats
# 同时生成 HTML 和 CSV 报告
locust -f locustfile.py \
--host=https://erp.example.com \
--headless \
--users 100 \
--spawn-rate 10 \
--run-time 5m \
--html reports/report.html \
--csv reports/stats
分布式运行配置
1. Master 节点配置
# 启动 Master 节点
locust -f locustfile.py \
--host=https://erp.example.com \
--master \
--web-port=8089
# Master 节点配置参数:
# --master: 指定为 Master 节点
# --expect-workers: 期望的 Worker 节点数量(可选)
# --web-port: Web UI 端口
2. Worker 节点配置
# 启动 Worker 节点
locust -f locustfile.py \
--host=https://erp.example.com \
--worker \
--master-host=192.168.1.100
# Worker 节点配置参数:
# --worker: 指定为 Worker 节点
# --master-host: Master 节点地址
# --master-port: Master 节点端口(默认 5557)
3. 分布式运行示例
# Master 节点(192.168.1.100)
locust -f locustfile.py --host=https://erp.example.com --master --expect-workers=3
# Worker 节点 1(192.168.1.101)
locust -f locustfile.py --host=https://erp.example.com --worker --master-host=192.168.1.100
# Worker 节点 2(192.168.1.102)
locust -f locustfile.py --host=https://erp.example.com --worker --master-host=192.168.1.100
# Worker 节点 3(192.168.1.103)
locust -f locustfile.py --host=https://erp.example.com --worker --master-host=192.168.1.100
Web UI 监控指南
1. 访问 Web UI
启动 Locust 后,访问 http://localhost:8089 打开 Web UI。
2. 启动测试
在 Web UI 中:
- 输入目标用户数(Number of users)
- 输入用户生成速率(Spawn rate)
- 点击 "Start swarming" 开始测试
3. 监控指标
Web UI 提供以下监控指标:
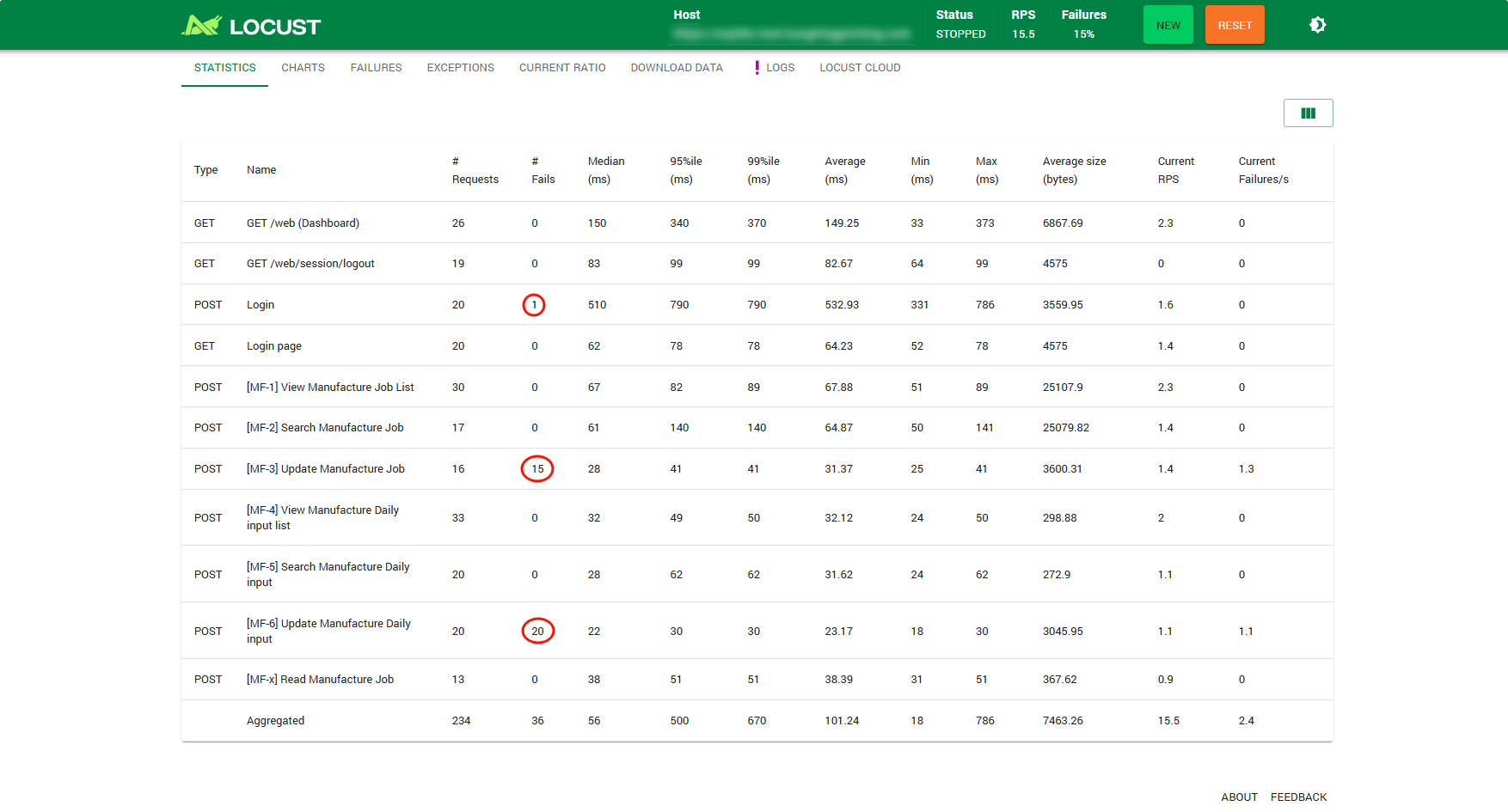
统计信息(Statistics):
- Request:请求路径
- Type:请求类型(GET/POST)
- Requests:请求总数
- Fails:失败次数
- Median:响应时间中位数
- 95%ile:95% 请求的响应时间
- 99%ile:99% 请求的响应时间
- Average:平均响应时间
- Min:最小响应时间
- Max:最大响应时间
- Average Size:平均响应大小
- Current RPS:当前每秒请求数
图表(Charts):
- 响应时间趋势图
- RPS(Requests Per Second)趋势图
- 失败率趋势图
失败请求(Failures):
- 显示失败的请求详情
- 错误类型和消息
异常(Exceptions):
- 显示测试过程中发生的异常
性能指标解读
1. 响应时间指标
- Median(中位数):50% 的请求响应时间小于此值
- 95%ile(95 百分位):95% 的请求响应时间小于此值
- 99%ile(99 百分位):99% 的请求响应时间小于此值
- Average(平均值):所有请求的平均响应时间
- Min/Max(最小/最大):响应时间的最小值和最大值
2. 吞吐量指标
- Current RPS:当前每秒请求数
- Requests:总请求数
- Fails:失败请求数
3. 性能评估标准
响应时间标准:
- 优秀:< 200ms
- 良好:200ms - 500ms
- 可接受:500ms - 1000ms
- 需优化:> 1000ms
成功率标准:
- 优秀:> 99.9%
- 良好:> 99%
- 可接受:> 95%
- 需优化:< 95%
代码示例
完整的用户类示例
"""
完整的用户类示例
展示如何定义具体的用户类型
"""
import logging
from locust import HttpUser, task, between
from utils.user_loader import ExcelUserLoader
from taskset.purchase_request import PurchaseRequestTask
from taskset.purchase_order import PurchaseOrderTask
logger = logging.getLogger(__name__)
# 初始化用户数据加载器(类级别,避免重复加载)
purchase_user_loader = ExcelUserLoader("./user_data/purchase_users.xlsx")
class PurchaseUser(HttpUser):
"""
采购用户类
模拟采购部门的用户行为
"""
weight = 10 # 权重:10个此类用户 vs 其他用户类型的比例
abstract = False # 可以实例化
wait_time = between(1, 5)
host = "https://erp.example.com"
def __init__(self, *args, **kwargs):
"""
初始化用户
从 Excel 文件随机获取用户数据
"""
super().__init__(*args, **kwargs)
# 设置 Odoo 配置
self.database = "odoo"
# 从 Excel 随机获取用户
user = purchase_user_loader.get_random_user()
self.username = user.get('login', '')
self.password = str(user.get('password', ''))
logger.info(f"初始化采购用户: {self.username}")
# 关联任务集
tasks = [PurchaseRequestTask, PurchaseOrderTask]
@task(5)
def view_dashboard(self):
"""查看仪表板"""
if not self.is_logged_in():
logger.warning("用户未登录,跳过 Dashboard 请求")
return
with self.client.get(
"/web",
name="GET /web (Dashboard)",
allow_redirects=True,
catch_response=True
) as response:
if response.status_code == 200:
response.success()
logger.debug("Dashboard 加载成功")
else:
response.failure(f"Dashboard 加载失败: HTTP {response.status_code}")
任务集示例
"""
完整的任务集示例
展示如何实现业务场景的任务集
"""
import random
import logging
from datetime import datetime
from typing import Optional, List, Dict
from locust import TaskSet, task, between
logger = logging.getLogger(__name__)
class PurchaseRequestTask(TaskSet):
"""
采购申请任务集
完整的任务集实现,包含:
- 查看列表
- 浏览详情
- 更新操作
- 创建操作
"""
wait_time = between(1, 5)
model = "purchase.request"
def __init__(self, parent):
"""初始化任务集"""
super().__init__(parent)
self.request_list = [] # 缓存的采购申请列表
self._cache = {} # 其他数据缓存
@task(20)
def view_request_list(self):
"""查看采购申请列表"""
try:
result = self.user.call_kw(
model=self.model,
method="web_search_read",
args=[],
kwargs={
"limit": 50,
"offset": 0,
"domain": [],
"fields": ["id", "name", "date", "state", "amount_total"],
"order": "create_date desc",
"count_limit": 10000,
},
name="Purchase Request - View List"
)
if result and "records" in result:
self.request_list = result["records"][:50]
logger.debug(f"加载了 {len(self.request_list)} 条采购申请")
except Exception as e:
logger.error(f"查看采购申请列表失败: {e}", exc_info=True)
@task(15)
def browse_request_detail(self):
"""浏览采购申请详情"""
if not self.request_list:
self.view_request_list()
if self.request_list:
request = random.choice(self.request_list)
result = self.user.call_kw(
model=self.model,
method="read",
args=[[request["id"]]],
kwargs={
"fields": [
"id", "name", "date", "state",
"partner_id", "amount_total", "line_ids"
]
},
name="Purchase Request - Read Detail"
)
if result:
logger.debug(f"浏览采购申请: {result[0].get('name', '')}")
@task(10)
def update_request(self):
"""更新采购申请"""
if not self.request_list:
self.view_request_list()
# 只更新自己创建的申请
my_requests = self.user.call_kw(
model=self.model,
method="search_read",
args=[],
kwargs={
"limit": 10,
"domain": [["create_uid", "=", self.user.uid]],
"fields": ["id", "name"]
},
name="Purchase Request - Search My Requests"
)
if my_requests:
request = random.choice(my_requests)
update_result = self.user.call_kw(
model=self.model,
method="write",
args=[[request["id"]], {
"note": f"Locust测试更新 - {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}"
}],
name="Purchase Request - Update"
)
if update_result:
logger.info(f"成功更新采购申请: {request.get('name', '')}")
@task(5)
def create_request(self):
"""创建采购申请"""
try:
# 获取必要的基础数据
partner_id = self._get_partner()
product_id = self._get_product()
if not partner_id or not product_id:
logger.warning("无法获取创建采购申请所需的基础数据")
return
# 创建采购申请
vals = {
"partner_id": partner_id,
"date": datetime.now().strftime("%Y-%m-%d"),
"line_ids": [
(0, 0, {
"product_id": product_id,
"product_qty": random.randint(1, 10),
"price_unit": random.uniform(10.0, 1000.0),
})
],
"note": f"Locust测试创建 - {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}"
}
result = self.user.call_kw(
model=self.model,
method="create",
args=[vals],
name="Purchase Request - Create"
)
if result:
logger.info(f"成功创建采购申请: ID={result}")
except Exception as e:
logger.error(f"创建采购申请失败: {e}", exc_info=True)
def _get_partner(self) -> Optional[int]:
"""获取供应商(带缓存)"""
cache_key = "partners"
# 检查缓存
if cache_key in self._cache:
partners = self._cache[cache_key]
if partners:
return random.choice(partners)
# 从 API 获取
result = self.user.call_kw(
model="res.partner",
method="search",
args=[[["supplier_rank", ">", 0]]],
kwargs={"limit": 10},
name="Purchase Request - Get Partner"
)
# 更新缓存
if result:
self._cache[cache_key] = result
return random.choice(result) if result else None
def _get_product(self) -> Optional[int]:
"""获取产品(带缓存)"""
cache_key = "products"
# 检查缓存
if cache_key in self._cache:
products = self._cache[cache_key]
if products:
return random.choice(products)
# 从 API 获取
result = self.user.call_kw(
model="product.product",
method="search",
args=[[["purchase_ok", "=", True]]],
kwargs={"limit": 10},
name="Purchase Request - Get Product"
)
# 更新缓存
if result:
self._cache[cache_key] = result
return random.choice(result) if result else None
配置文件示例
Python 配置文件
# config/settings.py
"""
测试配置
"""
import os
from typing import Tuple
from pathlib import Path
class Settings:
"""测试配置类"""
# Odoo 服务器配置
ODOO_HOST = os.getenv("ODOO_HOST", "https://erp.example.com")
ODOO_DATABASE = os.getenv("ODOO_DATABASE", "odoo")
# 用户数据配置
USER_DATA_DIR = Path(__file__).parent.parent / "user_data"
# Locust 配置
DEFAULT_WAIT_TIME: Tuple[int, int] = (1, 5)
DEFAULT_WEIGHT = 1
# 日志配置
LOG_LEVEL = os.getenv("LOG_LEVEL", "INFO")
LOG_FORMAT = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
LOG_FILE = None
# 性能配置
MAX_CACHE_SIZE = 50
CACHE_TTL = 300 # 秒
# API 配置
DEFAULT_TIMEOUT = 30 # 秒
MAX_RETRIES = 3
@classmethod
def validate(cls):
"""验证配置"""
errors = []
if not cls.ODOO_HOST:
errors.append("ODOO_HOST 未设置")
if not cls.ODOO_DATABASE:
errors.append("ODOO_DATABASE 未设置")
if errors:
raise ValueError(f"配置错误: {', '.join(errors)}")
return True
YAML 配置文件
# config/environments.yaml
environments:
development:
host: "http://localhost:8069"
database: "odoo_dev"
log_level: "DEBUG"
testing:
host: "https://erp-test.example.com"
database: "odoo_test"
log_level: "INFO"
production:
host: "https://erp.example.com"
database: "odoo"
log_level: "WARNING"
settings:
default_wait_time: [1, 5]
max_cache_size: 50
cache_ttl: 300
default_timeout: 30
max_retries: 3
工具类示例
# utils/logger.py
"""
日志配置工具
"""
import logging
import sys
from pathlib import Path
from config.settings import Settings
def setup_logger(name: str = None, log_file: Path = None) -> logging.Logger:
"""
设置日志记录器
Args:
name: 日志记录器名称
log_file: 日志文件路径(可选)
Returns:
logging.Logger: 配置好的日志记录器
"""
logger = logging.getLogger(name or __name__)
logger.setLevel(getattr(logging, Settings.LOG_LEVEL))
# 避免重复添加处理器
if logger.handlers:
return logger
# 格式化器
formatter = logging.Formatter(Settings.LOG_FORMAT)
# 控制台处理器
console_handler = logging.StreamHandler(sys.stdout)
console_handler.setFormatter(formatter)
logger.addHandler(console_handler)
# 文件处理器(如果指定)
if log_file:
file_handler = logging.FileHandler(log_file, encoding='utf-8')
file_handler.setFormatter(formatter)
logger.addHandler(file_handler)
return logger
事件监听器示例
"""
事件监听器示例
用于测试开始和结束时的处理
"""
import logging
from locust import events
from locust.env import Environment
logger = logging.getLogger(__name__)
@events.test_start.add_listener
def on_test_start(environment: Environment, **kwargs):
"""
测试开始时的处理
Args:
environment: Locust 环境对象
**kwargs: 其他参数
"""
logger.info("=" * 60)
logger.info("压力测试开始")
logger.info(f"目标主机: {environment.host}")
logger.info(f"用户数: {environment.runner.target_user_count if environment.runner else 'N/A'}")
logger.info("=" * 60)
@events.test_stop.add_listener
def on_test_stop(environment: Environment, **kwargs):
"""
测试结束时的处理
Args:
environment: Locust 环境对象
**kwargs: 其他参数
"""
logger.info("=" * 60)
logger.info("压力测试结束")
if environment.stats:
stats = environment.stats.total
logger.info(f"总请求数: {stats.num_requests}")
logger.info(f"失败请求数: {stats.num_failures}")
logger.info(f"平均响应时间: {stats.avg_response_time:.2f}ms")
logger.info(f"最大响应时间: {stats.max_response_time:.2f}ms")
if stats.num_requests > 0:
success_rate = ((stats.num_requests - stats.num_failures)
/ stats.num_requests * 100)
logger.info(f"成功率: {success_rate:.2f}%")
logger.info("=" * 60)
@events.request.add_listener
def on_request(request_type, name, response_time, response_length, exception, **kwargs):
"""
请求完成时的处理
Args:
request_type: 请求类型(GET/POST)
name: 请求名称
response_time: 响应时间(毫秒)
response_length: 响应长度
exception: 异常对象(如果有)
**kwargs: 其他参数
"""
if exception:
logger.error(
f"请求失败: {name}, "
f"类型: {request_type}, "
f"响应时间: {response_time}ms, "
f"异常: {exception}"
)
故障排查
常见问题及解决方案
1. 登录失败
症状:
- 大量登录失败请求
- 错误信息:"登录失败: 无效的凭据"
可能原因:
- 用户名或密码错误
- 数据库名称错误
- CSRF token 获取失败
- 网络连接问题
解决方案:
def login(self) -> bool:
"""改进的登录方法,包含详细的错误处理"""
try:
# 步骤 1: 获取登录页面
response = self.client.get("/web/login", name="Login page")
if response.status_code != 200:
logger.error(f"获取登录页面失败: HTTP {response.status_code}")
logger.error(f"响应内容: {response.text[:500]}")
return False
# 步骤 2: 提取 CSRF token
csrf_anchor = '<input type="hidden" name="csrf_token" value="'
csrf_token = response.text.partition(csrf_anchor)[2].partition('"')[0]
if not csrf_token:
logger.error("无法提取 CSRF token")
logger.debug(f"响应内容片段: {response.text[:1000]}")
return False
# 步骤 3: 执行登录
login_data = {
"jsonrpc": "2.0",
"method": "call",
"id": random.randint(1, 1000000),
"csrf_token": csrf_token,
"params": {
"db": self.database,
"login": self.username,
"password": self.password,
}
}
with self.client.post(
"/web/session/authenticate",
json=login_data,
catch_response=True,
name="Login"
) as response:
if response.status_code == 200:
result = response.json()
if "result" in result and result["result"].get("uid"):
# 登录成功
self.uid = result["result"]["uid"]
logger.info(f"登录成功: UID={self.uid}")
response.success()
return True
else:
# 登录失败,记录详细信息
error_data = result.get("error", {})
error_msg = error_data.get("data", {}).get("name", "未知错误")
error_code = error_data.get("code", 0)
logger.error(
f"登录失败: {error_msg} (代码: {error_code})"
)
logger.debug(f"完整响应: {result}")
response.failure(f"登录失败: {error_msg}")
return False
else:
logger.error(f"登录请求失败: HTTP {response.status_code}")
logger.debug(f"响应内容: {response.text[:500]}")
response.failure(f"登录失败: HTTP {response.status_code}")
return False
except Exception as e:
logger.error(f"登录过程发生异常: {e}", exc_info=True)
return False
排查步骤:
- 验证用户名和密码是否正确
- 验证数据库名称是否正确
- 检查网络连接是否正常
- 查看 Locust 日志获取详细错误信息
- 使用浏览器手动登录验证 Odoo 服务器是否正常
2. API 调用失败
症状:
call_kw返回 None- 错误信息:"API 错误: ..."
可能原因:
- 用户未登录
- 权限不足
- 模型或方法不存在
- 参数错误
- 网络超时
解决方案:
def call_kw(self, model: str, method: str, args=None, kwargs=None, name=None, timeout=None):
"""改进的 call_kw 方法,包含详细的错误处理"""
# 检查登录状态
if not self.is_logged_in():
logger.warning("用户未登录,无法调用 API")
return None
# 构建请求数据
request_data = {
"jsonrpc": "2.0",
"method": "call",
"params": {
"model": model,
"method": method,
"args": args or [],
"kwargs": kwargs or {},
"context": self.user_context
},
"id": random.randint(1, 1000000)
}
request_name = name or f"{model}.{method}"
try:
with self.client.post(
"/web/dataset/call_kw",
json=request_data,
catch_response=True,
name=request_name,
timeout=timeout or 30
) as response:
if response.status_code == 200:
result = response.json()
if "result" in result:
response.success()
return result["result"]
elif "error" in result:
# 详细记录错误信息
error = result["error"]
error_msg = error.get("message", "Unknown error")
error_data = error.get("data", {})
error_code = error.get("code", 0)
logger.error(
f"API 调用失败: {request_name}\n"
f" 错误消息: {error_msg}\n"
f" 错误代码: {error_code}\n"
f" 错误数据: {error_data}\n"
f" 请求参数: model={model}, method={method}"
)
response.failure(f"API 错误: {error_msg}")
return None
else:
logger.error(f"响应格式异常: {result}")
response.failure("响应格式异常")
return None
else:
logger.error(
f"HTTP 请求失败: {request_name}\n"
f" 状态码: {response.status_code}\n"
f" 响应内容: {response.text[:500]}"
)
response.failure(f"HTTP {response.status_code}")
return None
except Exception as e:
logger.error(
f"API 调用异常: {request_name}\n"
f" 异常类型: {type(e).__name__}\n"
f" 异常消息: {str(e)}",
exc_info=True
)
return None
排查步骤:
- 确认用户已登录(检查
self.uid) - 验证模型名称和方法名称是否正确
- 检查参数格式是否正确
- 查看 Odoo 服务器日志
- 使用 Odoo 的 Web 界面手动执行相同操作验证
3. 性能问题
症状:
- 响应时间过长
- 吞吐量下降
- 大量请求超时
可能原因:
- Odoo 服务器负载过高
- 数据库查询慢
- 网络延迟
- 测试脚本效率低
解决方案:
# 1. 优化查询(限制查询数量和字段)
result = self.user.call_kw(
model="purchase.order",
method="search_read",
args=[],
kwargs={
"limit": 50, # 限制查询数量
"fields": ["id", "name", "state"], # 只查询需要的字段
"domain": [["state", "=", "draft"]], # 使用索引字段
},
name="Optimized Query"
)
# 2. 使用缓存
def _get_partners(self):
"""获取合作伙伴(带缓存)"""
cache_key = "partners"
if cache_key in self._cache:
return self._cache[cache_key]
result = self.user.call_kw(...)
if result:
self._cache[cache_key] = result
return result
# 3. 批量操作
# ❌ 不好:逐个更新
for item in items:
self.user.call_kw(model="...", method="write", args=[[item.id], {...}])
# ✅ 好:批量更新
self.user.call_kw(
model="...",
method="write",
args=[item_ids, values] # 批量更新
)
排查步骤:
- 检查 Odoo 服务器 CPU 和内存使用率
- 检查数据库性能(慢查询日志)
- 检查网络延迟
- 优化测试脚本(减少不必要的请求)
- 使用 Locust 的分布式模式分散负载
4. 内存泄漏
症状:
- 长时间运行后内存占用持续增长
- 系统变慢
可能原因:
- 缓存无限增长
- 对象未释放
- 日志文件过大
解决方案:
class MyTaskSet(TaskSet):
MAX_CACHE_SIZE = 50
def __init__(self, parent):
super().__init__(parent)
self._cache = {}
def _add_to_cache(self, key: str, data: any):
"""添加缓存,限制大小"""
if len(self._cache) >= self.MAX_CACHE_SIZE:
# 移除最旧的项(FIFO)
oldest_key = next(iter(self._cache))
del self._cache[oldest_key]
self._cache[key] = data
def _clear_cache(self):
"""清理缓存"""
self._cache.clear()
排查步骤:
- 使用内存分析工具(如
memory_profiler)定位问题 - 限制缓存大小
- 定期清理缓存
- 检查日志配置,避免日志文件无限增长
性能优化
减少不必要的请求
✅ 推荐做法
class PurchaseRequestTask(TaskSet):
def __init__(self, parent):
super().__init__(parent)
self._partners_cache = None
self._products_cache = None
def _get_partners(self):
"""获取合作伙伴(使用缓存)"""
if self._partners_cache is None:
self._partners_cache = self.user.call_kw(
model="res.partner",
method="search",
args=[[["supplier_rank", ">", 0]]],
kwargs={"limit": 10},
name="Get Partners"
)
return self._partners_cache
❌ 避免做法
def _get_partners(self):
"""每次都查询"""
return self.user.call_kw(...) # 每次都查询,没有缓存
批量操作优化
✅ 推荐做法
# 批量创建
line_vals = [
(0, 0, {"product_id": p1, "qty": 10}),
(0, 0, {"product_id": p2, "qty": 20}),
(0, 0, {"product_id": p3, "qty": 30}),
]
order_vals = {
"partner_id": partner_id,
"line_ids": line_vals, # 一次性创建多条记录
}
result = self.user.call_kw(
model="purchase.order",
method="create",
args=[order_vals],
name="Create Order with Lines"
)
❌ 避免做法
# 逐个创建
order_id = self.user.call_kw(...) # 创建订单
self.user.call_kw(...) # 添加第1行
self.user.call_kw(...) # 添加第2行
self.user.call_kw(...) # 添加第3行
查询优化
1. 限制查询数量
# ✅ 好:限制查询数量
result = self.user.call_kw(
model="purchase.order",
method="search_read",
args=[],
kwargs={"limit": 50}, # 只查询50条
name="Get Orders"
)
# ❌ 不好:查询所有数据
result = self.user.call_kw(
model="purchase.order",
method="search_read",
args=[],
kwargs={}, # 没有限制,可能返回大量数据
name="Get Orders"
)
2. 只查询需要的字段
# ✅ 好:只查询需要的字段
result = self.user.call_kw(
model="purchase.order",
method="search_read",
args=[],
kwargs={
"fields": ["id", "name", "state"], # 只查询3个字段
},
name="Get Orders"
)
# ❌ 不好:查询所有字段
result = self.user.call_kw(
model="purchase.order",
method="search_read",
args=[],
kwargs={
"fields": [], # 空列表表示所有字段
},
name="Get Orders"
)
3. 使用索引字段构建查询域
# ✅ 好:使用索引字段(如 id, name)
domain = [["id", ">", 1000]]
# ❌ 不好:使用非索引字段
domain = [["note", "ilike", "test"]]
连接池配置
Locust 的 HttpUser 默认使用连接池,但可以优化:
from locust.contrib.fasthttp import FastHttpUser
class OdooUser(FastHttpUser): # 使用 FastHttpUser 提升性能
"""
使用 FastHttpUser 替代 HttpUser
FastHttpUser 使用 gevent 的 HTTP 客户端,性能更好
"""
abstract = True
wait_time = between(1, 5)
host = "https://erp.example.com"
# 可以配置连接池参数
# connection_timeout = 10
# network_timeout = 10
缓存策略
1. 时间戳缓存(TTL)
import time
class MyTaskSet(TaskSet):
def __init__(self, parent):
super().__init__(parent)
self._cache = {}
self._cache_ttl = 300 # 缓存有效期 5 分钟
def _get_cached_data(self, key: str):
"""获取缓存数据(带 TTL)"""
if key in self._cache:
data, timestamp = self._cache[key]
if time.time() - timestamp < self._cache_ttl:
return data
else:
# 缓存过期,删除
del self._cache[key]
return None
def _set_cached_data(self, key: str, data: any):
"""设置缓存数据"""
self._cache[key] = (data, time.time())
2. LRU 缓存(限制大小)
from functools import lru_cache
class MyTaskSet(TaskSet):
@lru_cache(maxsize=50) # 最多缓存50个结果
def _get_partner_by_id(self, partner_id: int):
"""获取合作伙伴(带 LRU 缓存)"""
result = self.user.call_kw(
model="res.partner",
method="read",
args=[[partner_id]],
kwargs={"fields": ["id", "name"]},
name="Get Partner"
)
return result[0] if result else None
性能优化检查清单
- 减少不必要的 API 调用
- 使用缓存存储常用数据
- 限制查询数量和字段
- 使用批量操作
- 优化查询域(使用索引字段)
- 使用 FastHttpUser(如果需要更高性能)
- 配置合理的超时时间
- 限制缓存大小,避免内存泄漏
- 定期清理缓存
总结
本文档提供了使用 Locust 对 Odoo 进行压力测试的完整指南,包括:
- 架构设计:清晰的系统架构和组件设计
- 代码实现:完整的代码示例和最佳实践
- 配置管理:灵活的配置方案
- 运行监控:详细的运行和监控指南
- 故障排查:常见问题的解决方案
- 性能优化:实用的优化技巧
关键要点
- 模块化设计:将功能分离到不同模块,提高可维护性
- 最佳实践:遵循行业最佳实践,避免常见错误
- 错误处理:完善的错误处理和日志记录
- 性能优化:合理使用缓存和批量操作
- 可扩展性:易于添加新的用户类型和任务集
下一步
- 根据实际项目需求调整配置和代码
- 添加更多业务场景的任务集
- 集成到 CI/CD 流程
- 建立性能基准测试
- 持续优化和改进
文档版本:v1.0
最后更新:2025-11-05
维护者:Lucas